

简介:Unicode编码是一种标准化的文本表示方式,用于解决不同语言字符的全球表示问题。中文Unicode编码表是其重要组成部分,包含所有中文字符编码,确保跨平台一致识别。该表主要涵盖基本多文种平面的第2区,也有少量汉字和符号在其他辅助平面。表内汉字通过16进制Unicode码点表示,常转换为16位二进制字节序列以便计算机处理。在网页设计、数据库存储、文本处理和软件开发等领域中,正确使用Unicode编码至关重要。掌握中文Unicode编码对于IT人员在全球信息技术交流中至关重要。
1. Unicode编码定义及重要性
Unicode,全称统一码、万国码、单一码(Unicode),是一个定位于跨语言、跨平台的字符编码标准。它旨在用单一的编码方案解决全球所有字符的表示问题。Unicode不仅包括了常用的拉丁字母、数字和标点符号,还包括了中文、日文、韩文等东亚文字,以及多种古代文字和少数民族语言的字符。
Unicode编码的定义和特点
Unicode编码的定义基于字符集理论,为每个字符分配一个唯一的编码点(Code Point),这个点在统一的编码空间中,称为码位(Code Space)。标准的码位范围通常用十六进制表示,并以 U+ 开头,如 U+4E00 代表了汉字“一”的码位。Unicode的特点在于:
Unicode编码的发展历程
Unicode的起源可追溯到1988年,当时Unicode的目标是解决ASCII编码无法表示多语言字符的问题。Unicode联盟(Unicode Consortium)成立,制定了详细的编码标准,并发布了一系列版本。随着技术的发展,Unicode标准不断更新,增加了新的字符集,改进了编码方法,并逐步被各个操作系统、编程语言和国际标准采纳。
Unicode编码在现代信息处理中的重要性
在当今的全球信息社会中,Unicode的重要性愈发凸显。它在互联网上扮演着核心角色,如:
Unicode的广泛采用,不仅简化了信息处理流程,也促进了全球文化的交流和信息共享。在本章中,我们详细探讨了Unicode编码的定义、特点、发展历程和重要性,为后续章节的学习打下坚实的基础。
2. 中文Unicode编码表组成与范围 2.1 中文字符在Unicode中的分布 2.1.1 基本汉字的Unicode表示
Unicode编码为每个字符分配了一个唯一的编码点,基本汉字也不例外。在Unicode标准中,基本汉字占据了从U+4E00到U+9FFF这一大块连续的编码空间。这一部分的编码范围是涵盖了几乎全部的常用汉字,被广泛用于各种中文文本的处理。
举例来说 ,汉字“中”在Unicode中的表示是U+4E2D。任何支持Unicode的文本处理系统都能够识别和正确显示这个字符。
graph LR;
A[Unicode编码空间] --> B[基本汉字范围]
B --> C[常用汉字];
C --> D["中" (U+4E2D)];
2.1.2 扩展汉字及特殊符号的Unicode编码
除了基本汉字之外,Unicode还提供了扩展A、B、C、D等区段,用于收录其他未包含在基本汉字区段内的汉字,以及特殊符号、标点等字符。例如,扩展A区段包括了一些罕见汉字和古代文字。
特殊符号例如数学符号、货币符号等也有它们自己的编码点。例如,人民币符号“¥”在Unicode中的编码是U+00A5。
2.1.3 繁体字与简体字的编码对应关系
Unicode编码标准中对简体字和繁体字有明确的区分,但同时保证了两者之间的映射关系,使得简繁转换变得可行。简体字和繁体字在Unicode中并不是一一对应,而是有一个转换表来实现简繁转换。
2.2 Unicode编码的编码范围 2.2.1 Unicode编码空间的划分
Unicode编码空间被划分为17个平面,每个平面可包含65536个编码点。基本多语言平面(BMP)是第一平面,其编码点范围从U+0000到U+FFFF。对于中文字符,除了基本汉字占据BMP中的一个区域外,其他扩展汉字及符号等可能位于其他平面。
2.2.2 中文字符编码范围的确定
中文字符的编码范围主要集中在BMP内,从U+4E00到U+9FFF。这一区域内的每个编码点都对应一个特定的汉字或符号。确定一个字符的编码范围对于字符集的管理以及文本处理有重要作用。
2.2.3 与GB2312、GBK等其他编码标准的兼容性分析
中文编码的另一种常用标准是GB2312、GBK等,这些编码标准是中国国家标准化组织制定的中文字符编码标准。为了确保与这些旧标准的兼容性,Unicode在设计时考虑到了与它们的对应关系。Unicode编码和这些编码标准之间可以通过转换表进行互相转换。了解这一兼容性对于处理旧文本和迁移至Unicode编码体系至关重要。
3. 字符编码转换为二进制表示 3.1 字符编码的基本概念 3.1.1 字符、编码、字符集的定义
字符是信息交流的基本单位,例如字母、数字、标点符号以及一些特殊符号等。在计算机中,字符需要通过编码来转换成二进制形式以便处理和存储。编码是一种映射关系,它定义了字符和数字之间的对应关系,而字符集是一组字符的集合,包括了字符和相应的编码规则。
3.1.2 编码转换的意义和方法
编码转换的意义在于不同系统或应用之间交换数据时,能够正确地识别和显示字符。例如,将文本从一种编码格式(如GBK)转换为另一种(如UTF-8),以保证在不同的环境中显示相同的内容。常见的方法包括使用编程语言内置的编码转换库或调用系统的编码转换工具。
3.1.3 常见字符编码标准简介 3.2 Unicode编码到二进制的转换过程 3.2.1 Unicode编码的具体转换方法
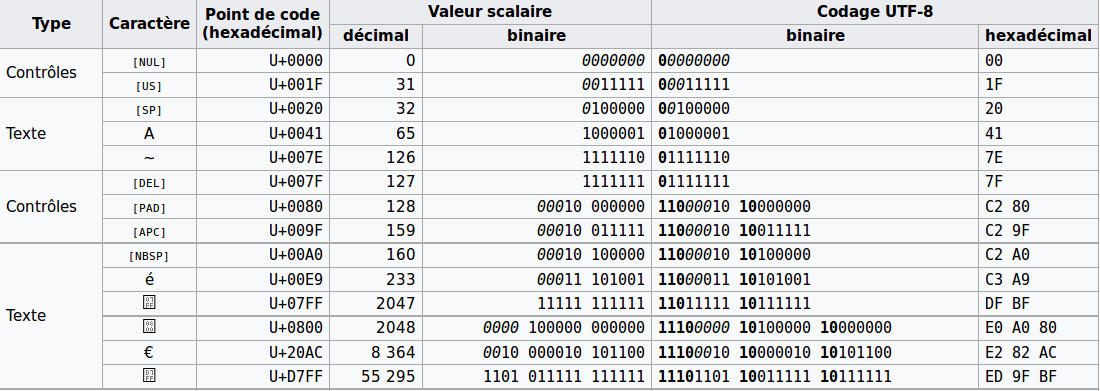
Unicode编码到二进制的转换相对简单直接。以UTF-8编码为例,它将Unicode码点(代码点)转换为对应长度的字节序列。例如,一个基本的多语言平面(BMP)字符的Unicode码点范围是U+0000到U+FFFF,它将直接使用与码点相同的二进制序列。对于超出这个范围的字符,如辅助平面字符,UTF-8会使用4个字节,并在字节的高位添加特殊标记。
3.2.2 转换过程中的注意事项
在进行Unicode编码转换时,必须注意以下几点:
- 确保转换工具或库支持Unicode的最新版本,以防止信息丢失。
- 注意字符编码的字节顺序标记(BOM),它可能会影响数据的解析。
- 避免编码不兼容引起的乱码问题,特别是在多语言环境中。
3.2.3 转换工具和软件的使用示例
以下是一些流行的命令行工具和库,它们可以用于在Unicode和二进制之间进行转换:
- iconv :一款命令行工具,支持多种编码的转换。
- Python :内置了对Unicode和UTF-8等编码的良好支持。
示例代码使用Python进行转换:
# Python 3 示例:将Unicode字符串转换为UTF-8编码的字节序列
unicode_string = "你好,世界!"
encoded_bytes = unicode_string.encode('utf-8')
print(encoded_bytes)
代码逻辑说明:
- unicode_string 定义了一个Unicode字符串。
- 使用 encode 方法和指定编码 'utf-8' ,将Unicode字符串转换为UTF-8编码的字节序列。
- print 函数用于输出转换后的字节序列。
输出结果是字节序列: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c\xef\xbc\x81'
该过程对于理解编码转换是基础且必要的,也是软件开发和文本处理中常见的操作。
4. Unicode编码在网页设计中的应用
Unicode编码在网页设计中的应用不仅关系到文本信息的正确显示,而且直接关联到网站的用户体验和国际化战略。这一章节将详细介绍Unicode编码在网页设计中的应用方法、字符集设定以及编码应用实例。
4.1 Unicode编码在网页设计中的必要性 4.1.1 解决乱码问题
在没有统一标准的编码环境下,中文网页经常会出现乱码,尤其是当用户使用不同的浏览器或者系统时。Unicode的引入,为网页设计提供了一套全球通用的字符编码解决方案。通过Unicode,网页设计师可以确保所有的用户看到的网页内容都是正确的。在HTML中使用 声明,就可以指定页面使用Unicode UTF-8编码,这样无论用户使用何种浏览器或操作系统,显示都不会产生乱码。
4.1.2 支持国际化和本地化需求
现代的网页设计不仅要考虑本土语言的显示问题,还需要考虑到支持多种语言。Unicode编码能够支持包括中文、日文、韩文等多种语言字符,这使得设计师可以轻松创建多语言版本的网站。对于本地化,Unicode的广泛支持确保了不同地区的用户均能无障碍地访问网站内容。
4.1.3 提升网站的可访问性和兼容性
Unicode提供了一个统一的编码系统,从而提高了网站的可访问性和兼容性。网站如果采用Unicode编码,就可以很容易地与各种浏览器、操作系统以及其他互联网技术无缝集成。此外,Unicode的使用可以简化网站的开发和维护工作,因为它减少了编码转换的需要,降低了出错的可能性。
4.2 HTML字符集设定与编码应用实例 4.2.1 设置HTML文档的字符集
要确保网页中的文本正确显示,首先需要在HTML文档中设置正确的字符集。HTML5中的字符集声明方法如下:
Unicode Example
这是Unicode编码的一个应用实例
在上述代码中, 指定了文档使用UTF-8编码,它是Unicode编码的一种变体,广泛支持所有字符集,并且是Web开发中推荐使用的字符集。
4.2.2 CSS和JavaScript中的Unicode应用
在CSS或JavaScript中处理Unicode字符也非常简单。例如,直接在CSS中设置字体时,可以这样指定:
p {
font-family: "宋体", "SimSun", "\5B8B\4F53", sans-serif;
}
在JavaScript中引用Unicode字符也很直接:
let message = "\u4F60\u597D"; // 输出"你好"
4.2.3 实际案例分析和问题解决
在实际案例中,Unicode的使用可能会遇到一些问题,例如在老版本的浏览器或者特殊环境下,可能不支持Unicode。针对这种情况,我们可以使用一些策略,如回退策略:
function supportsUnicode() {
try {
let canvas = document.createElement("canvas");
canvas.getContext("2d").drawImage(document.body, 0, 0);
return true;
} catch(e) {
return false;
}
}
如果发现不支持Unicode,则可以切换到其他字符集或者使用图片来展示文字。这样的回退机制可以确保在不支持Unicode的环境中,用户仍然能够看到页面上的文字信息。
Unicode编码在网页设计中的应用是网站国际化和全球用户体验的重要组成部分。通过对Unicode的正确设置和使用,设计师和开发者可以创造一个既美观又功能强大的网页环境,满足不同语言用户的阅读需求。
5. Unicode在数据库、文本处理和软件开发中的应用 5.1 Unicode在数据库中的应用
在数据库管理中,字符编码的选择直接关系到数据的准确性和一致性。Unicode的出现为数据库设计带来了革命性的改变,特别是多语言数据库的应用场景。
5.1.1 数据库字符集和排序规则的设定
数据库的字符集决定了它可以存储的数据类型。使用Unicode作为字符集,数据库能够支持全球绝大多数语言,无需担心数据在不同国家和区域间的兼容性问题。例如,在MySQL数据库中,可以选择 utf8mb4 作为字符集,它支持完整Unicode范围的编码。
ALTER DATABASE example_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
上述SQL语句将数据库 example_db 的字符集和排序规则更改为支持Unicode的 utf8mb4 。
5.1.2 Unicode在多语言数据库设计中的作用
在多语言数据库设计中,Unicode的作用尤为显著。通过使用Unicode,设计师可以确保所有语言的数据都能够得到妥善的存储和检索,无论数据的语言多么罕见或复杂。
5.1.3 数据库中字符编码迁移的策略
随着系统升级和国际化需求的增加,字符编码迁移成为数据库维护中的常见任务。Unicode提供了一个平台无关的编码标准,有助于在迁移过程中减少数据丢失的风险。迁移策略应当包括数据的备份、测试和验证迁移效果等步骤。
5.2 Unicode在文本处理中的应用
文本处理工具和程序通常需要处理多种语言和字符编码的数据。Unicode提供了一个统一的平台,简化了文本处理的复杂性。
5.2.1 文本编辑器和处理工具的Unicode支持
现代文本编辑器,如Visual Studio Code、Notepad++等,都支持Unicode。它们能够打开和编辑来自不同语言环境的文本文件,而不需要担心字符显示不正确。
5.2.2 文本文件编码转换和处理
文本文件的编码转换是一个常见的需求,尤其是在处理历史遗留数据时。工具如 iconv 或编程语言中的标准库(如Python的 codecs 模块)可以用来转换文件编码。
import codecs
with open('example.txt', 'r', encoding='utf-8') as f:
content = f.read()
with open('example转换.txt', 'w', encoding='gbk') as f:
f.write(content)
上述Python代码示例展示了如何将一个UTF-8编码的文本文件转换为GBK编码。
5.2.3 Unicode在文本分析和自然语言处理中的应用
Unicode不仅在文本的存储和显示上发挥作用,它还为文本分析和自然语言处理提供了坚实的基础。例如,文本挖掘和机器翻译系统都依赖于精确的字符编码来解析输入,并生成准确的输出。
5.3 Unicode在软件开发中的应用
软件开发中的国际化和本地化工作依赖于字符编码的正确处理,以确保软件在全球范围内的可用性和一致性。
5.3.1 软件国际化和本地化中Unicode的重要性
软件国际化(I18n)和本地化(L10n)是确保软件在全球市场成功的关键步骤。Unicode是国际化软件的基础,使得开发者能够无需更改源代码即可适应不同地区的语言和文化差异。
5.3.2 开发工具和编程语言中的Unicode支持
几乎所有的现代编程语言都内置了对Unicode的支持。例如,在JavaScript中,字符串操作都是基于Unicode的。而开发工具,如IDEs,通常支持Unicode编码的源文件,并提供相应的编码显示和处理功能。
5.3.3 Unicode编码问题的调试和优化技巧
尽管Unicode提供了广泛的支持,但在实际应用中仍然可能会遇到编码问题。调试Unicode问题通常需要对字符集、编码转换和排序规则有深入的理解。优化技巧包括使用标准库函数处理文本,避免直接操作字节数据,以及确保开发环境中正确使用Unicode编码。
简介:Unicode编码是一种标准化的文本表示方式,用于解决不同语言字符的全球表示问题。中文Unicode编码表是其重要组成部分,包含所有中文字符编码,确保跨平台一致识别。该表主要涵盖基本多文种平面的第2区,也有少量汉字和符号在其他辅助平面。表内汉字通过16进制Unicode码点表示,常转换为16位二进制字节序列以便计算机处理。在网页设计、数据库存储、文本处理和软件开发等领域中,正确使用Unicode编码至关重要。掌握中文Unicode编码对于IT人员在全球信息技术交流中至关重要。