
https://arxiv.org/abs/2306.05817
这篇论文主要探讨了推荐系统(RS)如何从大型语言模型(LLM)中获益。论文首先指出,随着在线服务和网络应用的快速发展,推荐系统已成为缓解信息过载和提供个性化建议的关键工具。然而,尽管传统推荐系统(CRM)在过去几十年中取得了显著进展,但仍存在一些局限性,例如缺乏开放领域世界知识和难以理解用户潜在偏好和动机。
论文提出,大型语言模型(LLM)因其在各种自然语言处理(NLP)任务中展现出的通用智能和类人能力而备受关注。LLM的这些能力主要源于其广泛的开放世界知识、逻辑和常识推理能力以及对人类文化和社会的理解。因此,LLM的出现为推荐系统的设计提供了新的研究方向,即是否可以整合LLM的通用知识和能力来弥补CRM的局限性。
论文从两个正交方面系统地总结了现有的研究成果:LLM可以在推荐系统的哪些阶段发挥作用(“WHERE”问题),以及如何适应LLM以改进推荐系统(“HOW”问题)。对于“WHERE”问题,论文讨论了LLM在推荐系统的不同阶段(如特征工程、特征编码器、评分/排名函数、用户交互和管道控制器)可能扮演的角色。对于“HOW”问题,论文调查了训练和推理策略,并提出了两个细粒度的分类标准,即是否在训练期间调整LLM的参数,以及是否在推理阶段涉及传统推荐模型。
此外,论文还强调了在将LLM适应到推荐系统时面临的三个主要挑战:效率、有效性和伦理问题。最后,论文总结了调查结果,并讨论了LLM增强推荐系统的未来前景。为了进一步推动这一新兴方向的研究社区,作者还积极维护了一个GitHub仓库,收集了与此相关的论文和其他资源。
整体而言,这篇论文为理解大型语言模型如何增强推荐系统提供了一个全面的视角,并为未来的研究方向和实践提供了宝贵的指导。
cdsn文章解读:
https://blog.csdn.net/lichunericli/article/details/137519852
2.Collaborative Large Language Model for Recommender Systems (WWW 2024)-2023.2,被引用次数:7
论文链接:
https://arxiv.org/abs/2311.01343
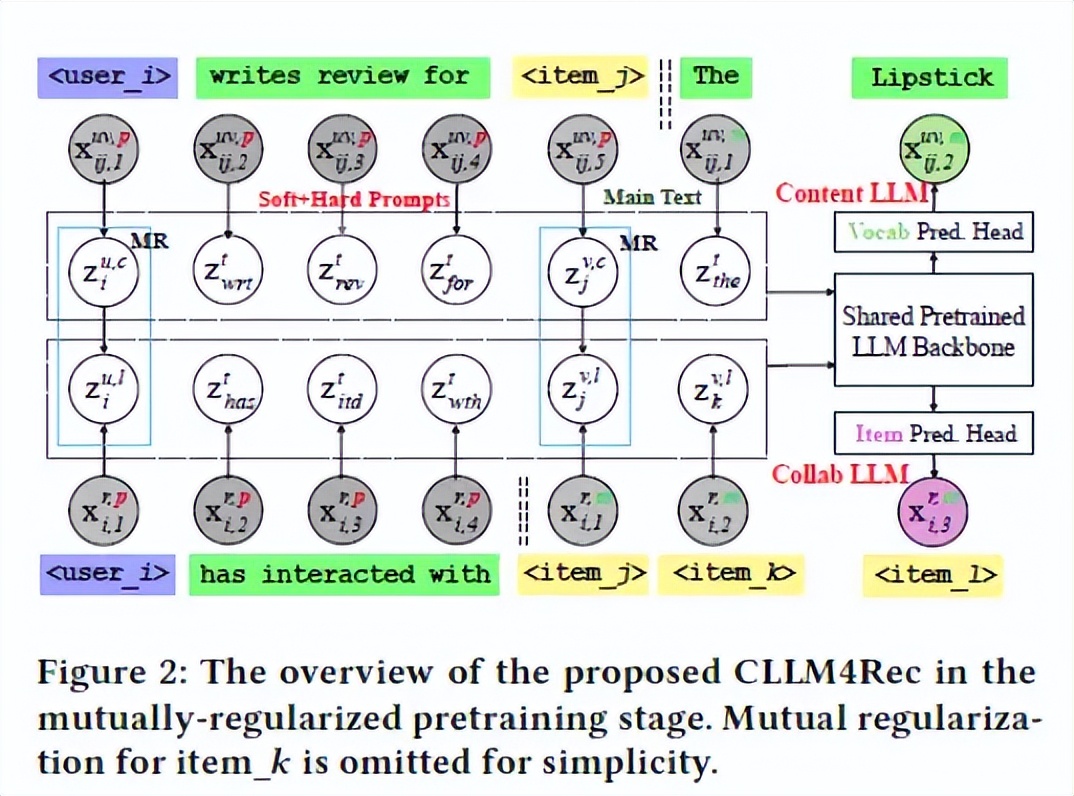
最近,对基于预训练大型语言模型(LLMs)的下一代推荐系统(RSs)的研究引起了广泛关注。然而,自然语言与推荐任务之间的语义鸿沟仍然没有得到很好的解决,尚存许多问题,如虚假关联的用户/物品描述符,对用户/物品数据的语言建模效果不佳,通过自回归进行的推荐效率低等。本文提出了CLLM4Rec,这是第一个紧密整合LLM范式和ID范式的生成式推荐系统,旨在同时解决上述挑战。本文首先通过使用用户/物品的ID词符来扩展预训练LLMs的词汇表,以更准确地建模用户/物品协同和内容上的语义。相应地,提出了一种新颖的软+硬的提示策略,通过在推荐系统特定的语料库上对语言建模,有效地学习用户/物品的表征,其中每个文档被分成一个包含异构软(用户/物品)词符和硬(词汇)词符的提示,以及一个由同质项词符或词汇词符组成的主要文本,以促进稳定而有效的语言建模。此外,引入了一种新颖的相互正则化策略,以鼓励CLLM4Rec从嘈杂的用户/物品内容中捕捉与推荐相关的信息。最后,本文提出了一种面向推荐的CLLM4Rec微调策略,其中在预训练的CLLM4Rec骨干中添加了一个具有多项式似然的物品预测头,以基于掩码用户-物品交互历史建立的软+硬提示来预测保留的物品,从而可以有效地生成多个物品的推荐而不产生幻觉。
3.Representation Learning with Large Language Models for Recommendation (WWW 2024)-2024.2,被引用次数:19
论文链接:
https://arxiv.org/abs/2310.15950
论文代码:
https://github.com/HKUDS/RLMRec
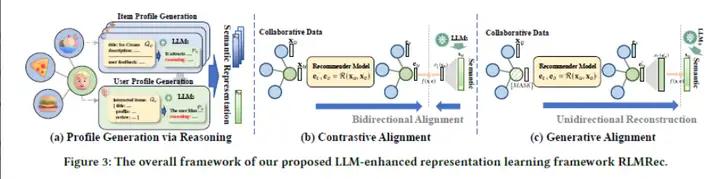
推荐系统在深度学习和图神经网络的辅助下取得了显著的进展,特别是在捕捉复杂的用户-物品关系方面。然而,一些基于图的推荐系统严重依赖基于ID的数据,可能忽视与用户和物品相关的有价值的文本信息,导致学到的表示不够信息丰富。此外,使用隐式反馈数据可能引入潜在的噪声和偏差,对用户偏好学习的有效性构成挑战。虽然在传统的基于ID的推荐系统中整合大型语言模型(LLMs)引起了广泛关注,但在实际推荐系统中的有效实施还需要解决可扩展性、文本依赖的局限性以及提示输入的限制等问题。为了解决这些问题,本文提出了一个模型不可知的框架RLMRec,旨在通过LLM强化表示学习来增强现有的推荐系统。本文提出了一种集成表示学习和LLMs的推荐范式,以捕捉用户行为和偏好的复杂语义方面。RLMRec整合辅助文本信号,利用LLMs进行用户/物品建模,并通过交叉视图对齐将LLMs的语义空间与协作关系信号对齐。该工作进一步通过最大化互信息展示了通过文本信号的理论基础,提高了表示的质量。本文通过将RLMRec与最先进的推荐模型集成,并分析了其对噪声数据的效率和稳健性。
4.ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation (WWW 2024)-2024.2,被引用次数:4
论文链接:
https://arxiv.org/abs/2308.11131
论文代码:
https://github.com/LaVieEnRose365/ReLLa
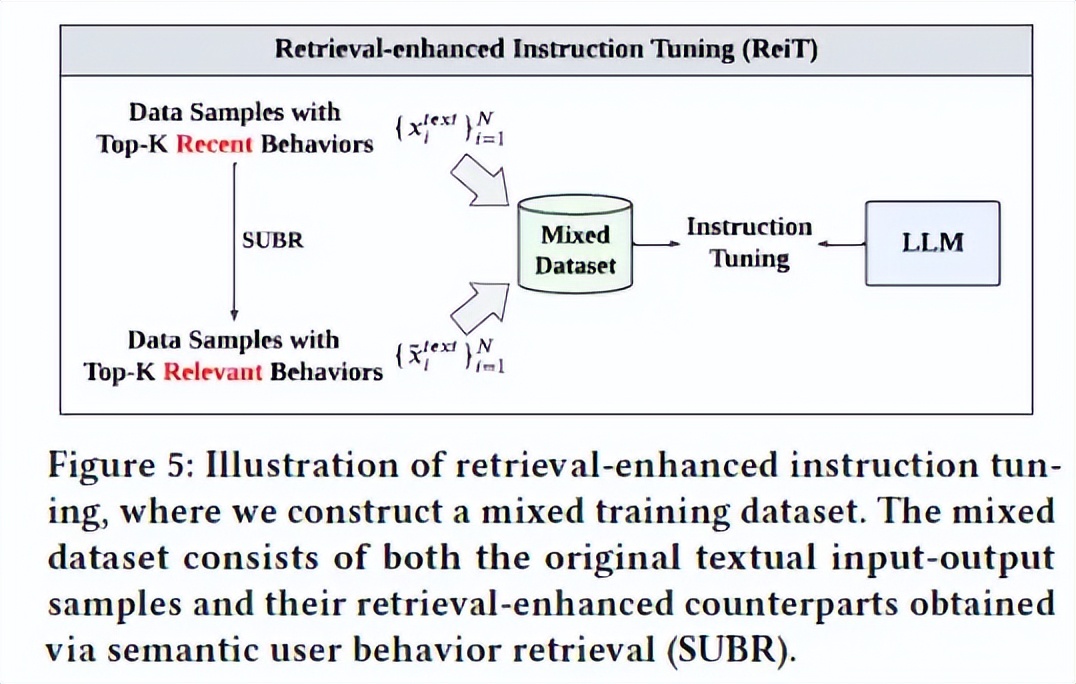
本文专注于调整和增强纯粹的大型语言模型以执行零样本和少样本推荐任务。首先,本文确定并针对推荐领域中的LLMs提出了长序列行为不理解的问题,即LLMs无法从长用户行为序列的文本上提取有用信息,即使上下文的长度远未达到LLMs的上下文限制。为了解决这个问题并提高LLMs的推荐性能,本文提出了一个新颖的框架,即检索增强大型语言模型(ReLLa),用于零样本和少样本设置的推荐任务。对于零样本推荐,本文执行语义用户行为检索(SUBR)以提高测试样本的数据质量,从而极大地降低了LLMs从用户行为序列中提取基本知识的难度。至于少样本推荐,本文进一步设计了检索增强指导调整(ReiT),通过采用SUBR作为训练样本的数据增强技术。具体而言,本文开发了一个混合训练数据集,包括原始数据样本和它们的检索增强对应物,同时在三个真实世界的公共数据集上进行了大量实验证明ReLLa相对于现有基准模型的优越性,以及它在生涯序列行为理解方面的能力。值得强调的是,仅使用不到10%的训练样本,少样本的ReLLa就能胜过传统的在整个训练集上训练的点击率模型(例如DCNv2,DIN,SIM)。
5.Could Small Language Models Serve as Recommenders? Towards Data-centric Cold-start Recommendation (WWW 2024)-2024.3,被引用次数:6
论文链接:
https://arxiv.org/abs/2306.17256
论文代码:
https://github.com/JacksonWuxs/PromptRec
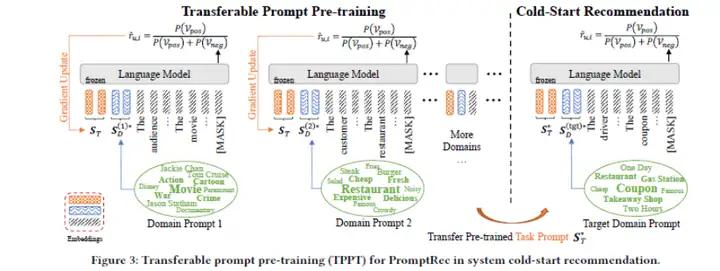
推荐系统帮助用户根据其历史行为找到与其兴趣相匹配的信息。然而,在缺乏历史用户-物品交互历史的情况下,生成个性化推荐变得具有挑战性,这对初创公司来说是一个实际问题,被称为系统冷启动推荐。目前的研究主要解决用户或物品冷启动情景,但对系统冷启动缺乏解决方案。为了解决这个问题,本文首先提出了PromptRec,这是一种基于语言模型的上下文学习的简单而有效的方法,将推荐任务转化为自然语言中包含用户和物品概况的情感分析任务。然而,这种天真的策略严重依赖于大型语言模型中出现的强大的上下文学习能力,这可能导致在线推荐的显著延迟。为了填补这一空白,本文提出了一个理论框架,以形式化上下文推荐和语言建模之间的关系。基于这一框架,本文提出了通过数据为中心的流程来增强小型语言模型,其中包括:(1)构建用于模型预训练的精制语料库;(2)通过提示预训练构建分解的提示模板。它们分别对应于训练数据和推断数据的开发。为了评估所提出的方法,本文引入了一个冷启动推荐基准,并结果表明,增强的小型语言模型在推断时间仅为大型模型的约17%的情况下,可以取得相近的冷启动推荐性能。
6.AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems (WWW 2024)-2023.10,被引用次数:14
论文链接:
https://arxiv.org/abs/2310.09233
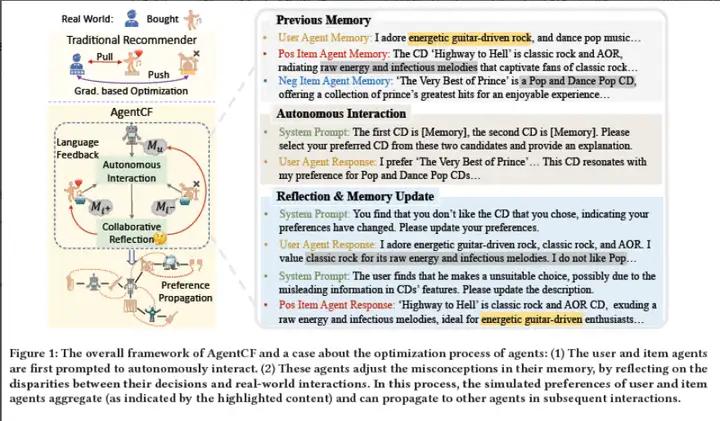
大语言模型强大的决策能力展现了作为人类代理的潜力。然而现有工作关注于模拟人类对话,而人类非语言行为的模拟,例如推荐系统中的物品点击,尽管可以隐式的展现用户偏好以及增强用户建模,尚没有被深入探索。本文认为主要原因在于语言建模和行为建模的差异以及大语言模型对用户-物品关系缺乏理解。为了解决这个问题,本文提出了AgentCF,通过基于智能体的协同过滤来模拟推荐系统中的用户-物品交互行为。本文将用户和物品都模拟为智能体,并利用协同学习的方式同时对二者进行优化。具体来说,在每个时间步,首先提示用户和物品智能体进行自主交互。然后,基于智能体交互决策和真实世界交互记录的差异,本文提示智能体协同地反思和调节错误的模拟偏好信息,从而学习和建模用户和物品之间的关系。在后续交互过程中,这些智能体进一步将习得的偏好传播给其余的智能体,隐式的建模了协同过滤。基于这个框架,本文模拟了多样化的用户-物品交互形式,结果表明这些智能体可以展示类人的行为。
7.Harnessing Large Language Models for Text-Rich Sequential Recommendation (WWW 2024)-2024.3,被引用次数:1
论文详情:
https://careersciencelab.com/seed-detail?id=62&from=publications
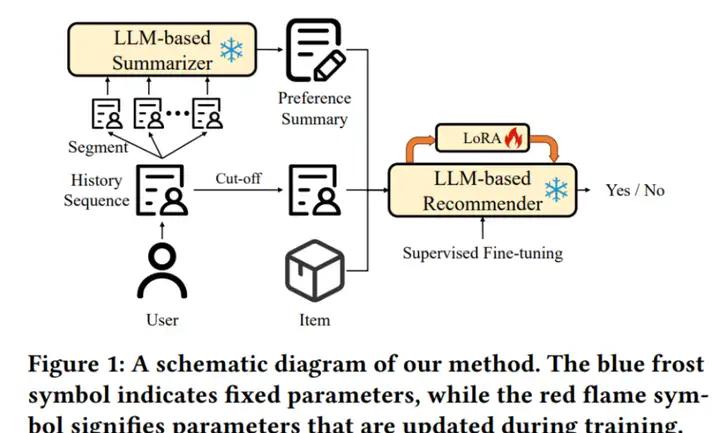
大语言模型已经在推荐系统领域引发了巨大的变革,展现了强大的用户行为理解能力。然而,目前的大语言模型受输入长度和计算复杂度限制的影响,在文本信息较长的富文本推荐场景下(如简历推荐场景),仍难以取得令人满意的效果。为了使大语言模型能够处理富文本序列推荐问题,本文首先将用户行为文本进行分块处理,并使用一个基于大语言模型的总结器对用户偏好进行总结。随后,用户偏好总结将和用户最近行为以及候选物品一起输入基于大语言模型的推荐器中,得到最终推荐结果。为了得到用户偏好总结,本文受到CNN和RNN思想的启发,分别提出了分层式总结和循环式总结两种用户偏好总结方法。分层式总结将多个块的总结文本拼接成一段,输入下一层总结器中;循环式总结将已生成的总结和新的块输入总结器中,得到更新后的总结,最终捕捉全部文本信息。在两个开源数据集上的实验验证了本文提出方法的效果。
8.Exploring Large Language Model for Graph Data Understanding in Online Job Recommendations (AAAI 2024)-2024.3,被引用次数:1
论文链接:
https://arxiv.org/abs/2307.05722
论文代码:
https://github.com/WLiK/GLRec
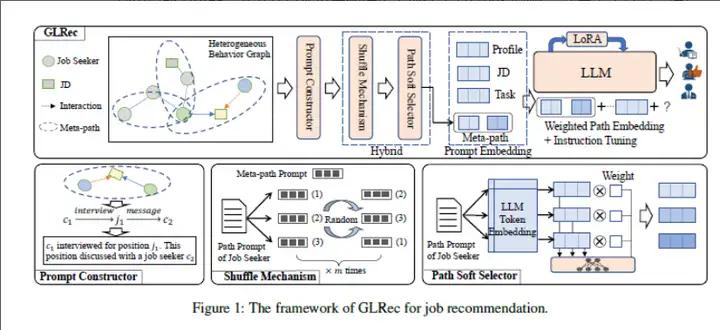
本文专注于揭示大型语言模型在理解行为图方面的能力,并利用这种理解来增强在线招聘中的推荐性能,包括推广某些超出分布(OOD)的申请。本文提出了一个新颖的框架,利用大型语言模型提供的丰富上下文信息和语义表示来分析行为图,揭示其中的潜在模式和关系。具体而言,本文提出了一个元路径提示构造器,帮助基于LLM的推荐系统首次理解行为图的语义,并设计了一个相应的路径增强模块来缓解基于路径的序列输入引入的提示偏见。通过促进这种能力,所提出的框架使个性化和准确的工作推荐对个别用户成为可能。本文在真实世界数据集上评估了方法的有效性,并展示了其提高推荐结果相关性和质量的能力。
9.Enhancing Job Recommendation through LLMbased Generative Adversarial Networks (AAAI 2024)-2023.7,被引用次数:14
论文链接:
https://arxiv.org/abs/2307.10747
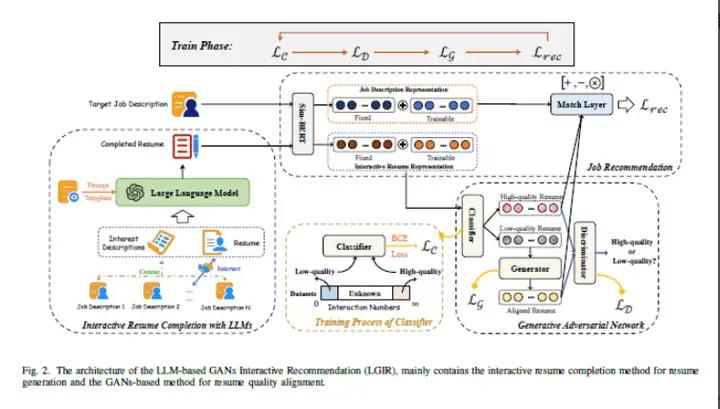
随着大型语言模型(LLMs)的快速发展,利用其中包含的丰富外部知识以及它们在文本处理和推理方面的强大能力,是完善用户简历以实现更准确推荐的一种有前景的方法。然而,直接利用LLMs来增强推荐结果并非一劳永逸的解决方案,因为LLMs可能面临虚构生成和少样本问题,从而降低简历完善的质量。 本文提出了一种基于LLMs的新方法,用于工作推荐。为了缓解LLMs虚构生成的影响,本文提取用户自我描述以外的准确和有价值的信息,这有助于LLMs更好地为简历完善对用户进行概括。具体来说,本文不仅从用户的自我描述中提取显式属性(例如技能、兴趣),还通过用户的行为推断出他们的隐式特征,以实现更准确和有意义的简历完善。然而,一些用户仍然面临由于互动记录稀缺而导致的少样本问题,这使得模型在生成高质量简历方面受到限制。为了解决这个问题,本文提出了通过生成对抗网络(GANs)将未配对的低质量生成的简历与高质量简历对齐,从而提高简历表示以获得更好的推荐结果。在三个大型真实世界的招聘数据集上进行的大量实验证明了所提出的方法的有效性。
10.LLMRG: Improving Recommendations through Large Language Model Reasoning Graphs (AAAI 2024)-2024.1,被引用次数:23
论文链接:
https://arxiv.org/abs/2308.10835
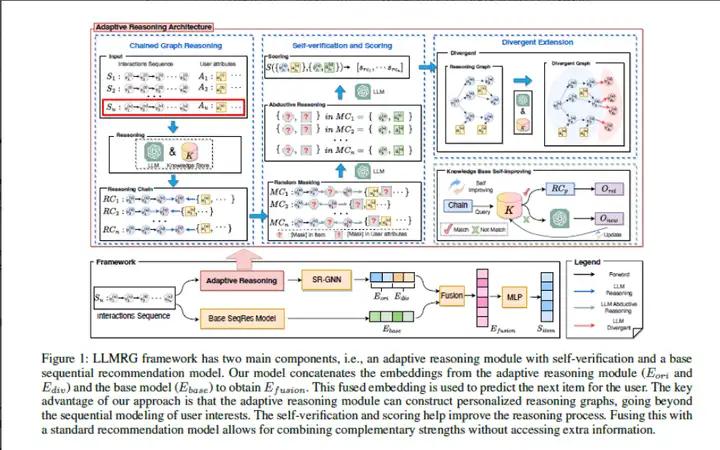
推荐系统旨在为用户提供相关的建议,但通常缺乏解释性,并且难以捕捉用户行为和概况之间的高级语义关系。本文提出了一种新颖的方法,利用大型语言模型(LLMs)构建个性化的推理图。这些图通过因果推理和逻辑推理将用户的概况和行为序列连接起来,以一种可解释的方式表示用户的兴趣。本文提出的方法:LLM推理图(LLMRG),包括四个组件:链式图推理、分歧扩展、自我验证和评分,以及知识库自我改进。由此产生的推理图使用图神经网络进行编码,作为附加输入用于改进传统的推荐系统,而无需额外的用户或物品信息。本文演示了LLMs如何通过个性化推理图实现更具逻辑性和可解释性的推荐系统。LLMRG允许推荐从既有的工程化推荐系统和LLMs派生的推理图中受益。最后通过在基准测试和真实场景中展示LLMRG在提升基本推荐模型方面的有效性。
11.LLMRec: Large Language Models with Graph Augmentation for Recommendation (WSDM 2024)-2024.1,被引用次数:35
论文链接:
https://arxiv.org/abs/2311.00423
论文代码:
https://github.com/HKUDS/LLMRec
csdn文章精读:
https://blog.csdn.net/weiwei935707936/article/details/134379924
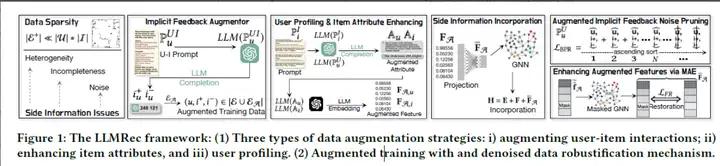
长期以来,数据稀疏性一直是推荐系统中的一个挑战,先前的研究尝试通过引入侧面信息来解决这个问题。然而,这种方法通常会引入诸如噪声、可用性问题和低数据质量等副作用,从而阻碍对用户偏好的准确建模,并对推荐性能产生不利影响。鉴于大型语言模型(LLMs)的最新进展,这些模型具有庞大的知识库和强大的推理能力,本文提出了一种新颖的框架,称为LLMRec,通过采用三种简单而有效的基于LLMs的图增强策略来增强推荐系统。LLMRec利用在线平台(如Netflix、MovieLens)中丰富的内容,以三种方式增强交互图:(i)加强用户-物品交互边,(ii)增强对物品节点属性的理解,以及(iii)从自然语言的角度直观地进行用户节点 解析。通过采用这些策略,本文解决了推荐系统中稀疏隐式反馈和低质量侧面信息所带来的挑战。此外,为了确保增强的质量,本文提出了一个去噪数据鲁棒化机制,其中包括噪声隐式反馈修剪和基于MAE的特征增强技术,有助于精炼增强的数据并提高其可靠性。此外,本文提供理论分析来支持LLMRec的有效性,并澄清方法在促进模型优化方面的优势。
12.ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models (WSDM 2024)-2023.8,被引用次数:23
论文链接:
https://arxiv.org/abs/2305.06566
论文代码:
https://github.com/Jyonn/ONCE
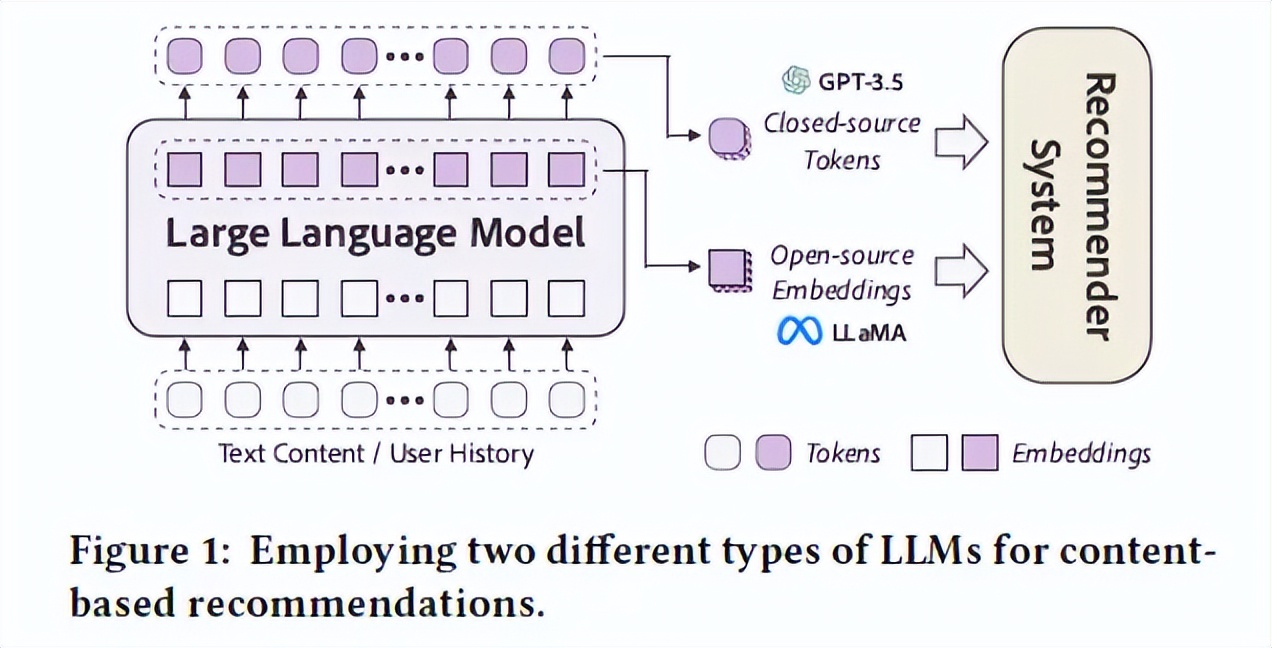
现有的推荐系统在理解物品内容方面面临着重大挑战。大型语言模型(LLMs)具有深层语义理解和来自预训练的广泛知识,已经在各种自然语言处理任务中证明了其有效性。本文探讨了利用开源和闭源LLMs来增强基于内容的推荐的潜力。对于开源LLMs,本文利用它们深层的结构作为内容编码器,丰富了嵌入级别的内容表示。对于闭源LLMs,本文采用提示技术在标记级别丰富训练数据。通过全面的实验,展示了两种类型的LLMs的高效性,并展示了它们之间的协同关系。值得注意的是,相对于现有最先进的推荐模型,实验结果可以观察到高达19.32%的显著相对改进。这些发现突显了开源和闭源LLMs在增强基于内容的推荐系统方面的巨大潜力。
13.【LLM+RS】LLM在推荐系统的实践应用(华为诺亚)-2024.1
LLM用于推荐主要还是解决推荐系统加入open domain 的知识。可以基于具体推荐场景数据做SFT。学习华为诺亚-技术分享-LLM在推荐系统的实践应用。
详细介绍文档:
https://mp.weixin.qq.com/s/pUrqdglF26ww1nDK9hANTA?from=singlemessage&isappinstalled=0&scene=1&clicktime=1699374085&enterid=1699374085
14.Prompting Large Language Models for Recommender Systems: A Comprehensive Framework and Empirical Analysis-2024.1,被引用次数:9